 . Function
. Function  is called the unit's affine function and is followed by a rectified linear unit, which clips negative values to zero:
is called the unit's affine function and is followed by a rectified linear unit, which clips negative values to zero:  . Such a computational unit is sometimes referred to as an “artificial neuron” and looks like:
. Such a computational unit is sometimes referred to as an “artificial neuron” and looks like:Terence Parr and Jeremy Howard
(Terence is a tech lead at Google and ex-Professor of computer/data science in University of San Francisco's MS in Data Science program. You might know Terence as the creator of the ANTLR parser generator. For more material, see Jeremy's fast.ai courses and University of San Francisco's Data Institute in-person version of the deep learning course.)
Please send comments, suggestions, or fixes to Terence.
Printable version (This HTML was generated from markup using bookish). A Chinese version is also available (content not verified by us).
Abstract
This paper is an attempt to explain all the matrix calculus you need in order to understand the training of deep neural networks. We assume no math knowledge beyond what you learned in calculus 1, and provide links to help you refresh the necessary math where needed. Note that you do not need to understand this material before you start learning to train and use deep learning in practice; rather, this material is for those who are already familiar with the basics of neural networks, and wish to deepen their understanding of the underlying math. Don't worry if you get stuck at some point along the way—-just go back and reread the previous section, and try writing down and working through some examples. And if you're still stuck, we're happy to answer your questions in the Theory category at forums.fast.ai. Note: There is a reference section at the end of the paper summarizing all the key matrix calculus rules and terminology discussed here.
Contents
Most of us last saw calculus in school, but derivatives are a critical part of machine learning, particularly deep neural networks, which are trained by optimizing a loss function. Pick up a machine learning paper or the documentation of a library such as PyTorch and calculus comes screeching back into your life like distant relatives around the holidays. And it's not just any old scalar calculus that pops up—-you need differential matrix calculus, the shotgun wedding of linear algebra and multivariate calculus.
Well... maybe need isn't the right word; Jeremy's courses show how to become a world-class deep learning practitioner with only a minimal level of scalar calculus, thanks to leveraging the automatic differentiation built in to modern deep learning libraries. But if you really want to really understand what's going on under the hood of these libraries, and grok academic papers discussing the latest advances in model training techniques, you'll need to understand certain bits of the field of matrix calculus.
For example, the activation of a single computation unit in a neural network is typically calculated using the dot product (from linear algebra) of an edge weight vector w with an input vector x plus a scalar bias (threshold): . Function is called the unit's affine function and is followed by a rectified linear unit, which clips negative values to zero: . Such a computational unit is sometimes referred to as an “artificial neuron” and looks like:
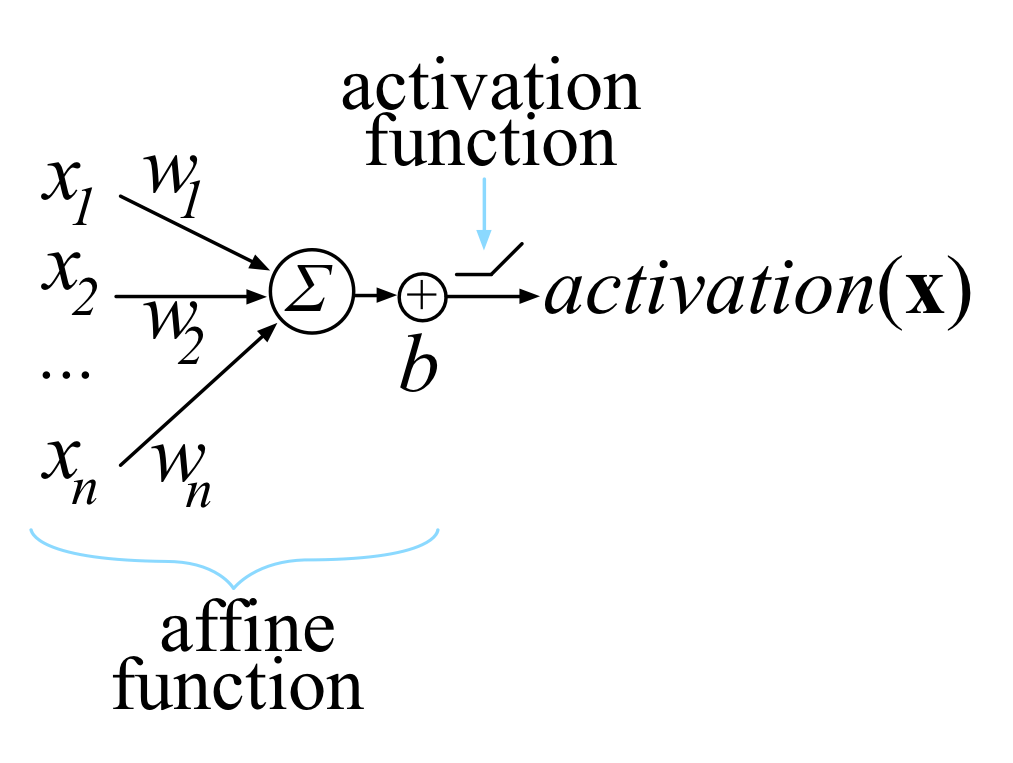
Neural networks consist of many of these units, organized into multiple collections of neurons called layers. The activation of one layer's units become the input to the next layer's units. The activation of the unit or units in the final layer is called the network output.
Training this neuron means choosing weights w and bias b so that we get the desired output for all N inputs x. To do that, we minimize a loss function that compares the network's final  with the
with the  (desired output of x) for all input x vectors. To minimize the loss, we use some variation on gradient descent, such as plain stochastic gradient descent (SGD), SGD with momentum, or Adam. All of those require the partial derivative (the gradient) of with respect to the model parameters w and b. Our goal is to gradually tweak w and b so that the overall loss function keeps getting smaller across all x inputs.
(desired output of x) for all input x vectors. To minimize the loss, we use some variation on gradient descent, such as plain stochastic gradient descent (SGD), SGD with momentum, or Adam. All of those require the partial derivative (the gradient) of with respect to the model parameters w and b. Our goal is to gradually tweak w and b so that the overall loss function keeps getting smaller across all x inputs.
If we're careful, we can derive the gradient by differentiating the scalar version of a common loss function (mean squared error):

But this is just one neuron, and neural networks must train the weights and biases of all neurons in all layers simultaneously. Because there are multiple inputs and (potentially) multiple network outputs, we really need general rules for the derivative of a function with respect to a vector and even rules for the derivative of a vector-valued function with respect to a vector.
This article walks through the derivation of some important rules for computing partial derivatives with respect to vectors, particularly those useful for training neural networks. This field is known as matrix calculus, and the good news is, we only need a small subset of that field, which we introduce here. While there is a lot of online material on multivariate calculus and linear algebra, they are typically taught as two separate undergraduate courses so most material treats them in isolation. The pages that do discuss matrix calculus often are really just lists of rules with minimal explanation or are just pieces of the story. They also tend to be quite obscure to all but a narrow audience of mathematicians, thanks to their use of dense notation and minimal discussion of foundational concepts. (See the annotated list of resources at the end.)
In contrast, we're going to rederive and rediscover some key matrix calculus rules in an effort to explain them. It turns out that matrix calculus is really not that hard! There aren't dozens of new rules to learn; just a couple of key concepts. Our hope is that this short paper will get you started quickly in the world of matrix calculus as it relates to training neural networks. We're assuming you're already familiar with the basics of neural network architecture and training. If you're not, head over to Jeremy's course and complete part 1 of that, then we'll see you back here when you're done. (Note that, unlike many more academic approaches, we strongly suggest first learning to train and use neural networks in practice and then study the underlying math. The math will be much more understandable with the context in place; besides, it's not necessary to grok all this calculus to become an effective practitioner.)
A note on notation: Jeremy's course exclusively uses code, instead of math notation, to explain concepts since unfamiliar functions in code are easy to search for and experiment with. In this paper, we do the opposite: there is a lot of math notation because one of the goals of this paper is to help you understand the notation that you'll see in deep learning papers and books. At the end of the paper, you'll find a brief table of the notation used, including a word or phrase you can use to search for more details.
Hopefully you remember some of these main scalar derivative rules. If your memory is a bit fuzzy on this, have a look at Khan academy vid on scalar derivative rules.
| Rule |  | Scalar derivative notation with respect to x | Example |
|---|---|---|---|
| Constant | c |  |  |
| Multiplication by constant | cf |  |  |
| Power Rule |  |  |  |
| Sum Rule |  |  |  |
| Difference Rule |  |  |  |
| Product Rule | fg |  |  |
| Chain Rule |  |  , let , let  |  |
There are other rules for trigonometry, exponentials, etc., which you can find at Khan Academy differential calculus course.
When a function has a single parameter, , you'll often see  and
and  used as shorthands for
used as shorthands for  . We recommend against this notation as it does not make clear the variable we're taking the derivative with respect to.
. We recommend against this notation as it does not make clear the variable we're taking the derivative with respect to.
You can think of  as an operator that maps a function of one parameter to another function. That means that
as an operator that maps a function of one parameter to another function. That means that  maps to its derivative with respect to x, which is the same thing as
maps to its derivative with respect to x, which is the same thing as  . Also, if
. Also, if  , then
, then  . Thinking of the derivative as an operator helps to simplify complicated derivatives because the operator is distributive and lets us pull out constants. For example, in the following equation, we can pull out the constant 9 and distribute the derivative operator across the elements within the parentheses.
. Thinking of the derivative as an operator helps to simplify complicated derivatives because the operator is distributive and lets us pull out constants. For example, in the following equation, we can pull out the constant 9 and distribute the derivative operator across the elements within the parentheses.

That procedure reduced the derivative of  to a bit of arithmetic and the derivatives of x and
to a bit of arithmetic and the derivatives of x and  , which are much easier to solve than the original derivative.
, which are much easier to solve than the original derivative.
Neural network layers are not single functions of a single parameter, . So, let's move on to functions of multiple parameters such as  . For example, what is the derivative of xy (i.e., the multiplication of x and y)? In other words, how does the product xy change when we wiggle the variables? Well, it depends on whether we are changing x or y. We compute derivatives with respect to one variable (parameter) at a time, giving us two different partial derivatives for this two-parameter function (one for x and one for y). Instead of using operator , the partial derivative operator is
. For example, what is the derivative of xy (i.e., the multiplication of x and y)? In other words, how does the product xy change when we wiggle the variables? Well, it depends on whether we are changing x or y. We compute derivatives with respect to one variable (parameter) at a time, giving us two different partial derivatives for this two-parameter function (one for x and one for y). Instead of using operator , the partial derivative operator is  (a stylized d and not the Greek letter
(a stylized d and not the Greek letter  ). So,
). So,  and
and  are the partial derivatives of xy; often, these are just called the partials. For functions of a single parameter, operator is equivalent to (for sufficiently smooth functions). However, it's better to use to make it clear you're referring to a scalar derivative.
are the partial derivatives of xy; often, these are just called the partials. For functions of a single parameter, operator is equivalent to (for sufficiently smooth functions). However, it's better to use to make it clear you're referring to a scalar derivative.
The partial derivative with respect to x is just the usual scalar derivative, simply treating any other variable in the equation as a constant. Consider function  . The partial derivative with respect to x is written
. The partial derivative with respect to x is written  . There are three constants from the perspective of : 3, 2, and y. Therefore,
. There are three constants from the perspective of : 3, 2, and y. Therefore,  . The partial derivative with respect to y treats x like a constant:
. The partial derivative with respect to y treats x like a constant:  . It's a good idea to derive these yourself before continuing otherwise the rest of the article won't make sense. Here's the Khan Academy video on partials if you need help.
. It's a good idea to derive these yourself before continuing otherwise the rest of the article won't make sense. Here's the Khan Academy video on partials if you need help.
To make it clear we are doing vector calculus and not just multivariate calculus, let's consider what we do with the partial derivatives  and
and  (another way to say
(another way to say  and
and  ) that we computed for . Instead of having them just floating around and not organized in any way, let's organize them into a horizontal vector. We call this vector the gradient of and write it as:
) that we computed for . Instead of having them just floating around and not organized in any way, let's organize them into a horizontal vector. We call this vector the gradient of and write it as:

So the gradient of is simply a vector of its partials. Gradients are part of the vector calculus world, which deals with functions that map n scalar parameters to a single scalar. Now, let's get crazy and consider derivatives of multiple functions simultaneously.
When we move from derivatives of one function to derivatives of many functions, we move from the world of vector calculus to matrix calculus. Let's compute partial derivatives for two functions, both of which take two parameters. We can keep the same from the last section, but let's also bring in  . The gradient for g has two entries, a partial derivative for each parameter:
. The gradient for g has two entries, a partial derivative for each parameter:

and

giving us gradient  .
.
Gradient vectors organize all of the partial derivatives for a specific scalar function. If we have two functions, we can also organize their gradients into a matrix by stacking the gradients. When we do so, we get the Jacobian matrix (or just the Jacobian) where the gradients are rows:

Welcome to matrix calculus!
Note that there are multiple ways to represent the Jacobian. We are using the so-called numerator layout but many papers and software will use the denominator layout. This is just transpose of the numerator layout Jacobian (flip it around its diagonal):

So far, we've looked at a specific example of a Jacobian matrix. To define the Jacobian matrix more generally, let's combine multiple parameters into a single vector argument:  . (You will sometimes see notation
. (You will sometimes see notation  for vectors in the literature as well.) Lowercase letters in bold font such as x are vectors and those in italics font like x are scalars. xi is the
for vectors in the literature as well.) Lowercase letters in bold font such as x are vectors and those in italics font like x are scalars. xi is the  element of vector x and is in italics because a single vector element is a scalar. We also have to define an orientation for vector x. We'll assume that all vectors are vertical by default of size
element of vector x and is in italics because a single vector element is a scalar. We also have to define an orientation for vector x. We'll assume that all vectors are vertical by default of size  :
:

With multiple scalar-valued functions, we can combine them all into a vector just like we did with the parameters. Let  be a vector of m scalar-valued functions that each take a vector x of length
be a vector of m scalar-valued functions that each take a vector x of length  where
where  is the cardinality (count) of elements in x. Each fi function within f returns a scalar just as in the previous section:
is the cardinality (count) of elements in x. Each fi function within f returns a scalar just as in the previous section:

For instance, we'd represent and from the last section as

It's very often the case that  because we will have a scalar function result for each element of the x vector. For example, consider the identity function
because we will have a scalar function result for each element of the x vector. For example, consider the identity function  :
:

So we have functions and parameters, in this case. Generally speaking, though, the Jacobian matrix is the collection of all  possible partial derivatives (m rows and n columns), which is the stack of m gradients with respect to x:
possible partial derivatives (m rows and n columns), which is the stack of m gradients with respect to x:

Each  is a horizontal n-vector because the partial derivative is with respect to a vector, x, whose length is
is a horizontal n-vector because the partial derivative is with respect to a vector, x, whose length is  . The width of the Jacobian is n if we're taking the partial derivative with respect to x because there are n parameters we can wiggle, each potentially changing the function's value. Therefore, the Jacobian is always m rows for m equations. It helps to think about the possible Jacobian shapes visually:
. The width of the Jacobian is n if we're taking the partial derivative with respect to x because there are n parameters we can wiggle, each potentially changing the function's value. Therefore, the Jacobian is always m rows for m equations. It helps to think about the possible Jacobian shapes visually:
![\begin{tabular}{c|ccl}
& \begin{tabular}[t]{c}
scalar\\
\framebox(18,18){$x$}\\
\end{tabular} & \begin{tabular}{c}
vector\\
\framebox(18,40){$\mathbf{x}$}
\end{tabular}\\
\hline
%\[\dimexpr-\normalbaselineskip+5pt]
\begin{tabular}[b]{c}
scalar\\
\framebox(18,18){$f$}\\
\end{tabular} &\framebox(18,18){$\frac{\partial f}{\partial {x}}$} & \framebox(40,18){$\frac{\partial f}{\partial {\mathbf{x}}}$}&\\
\begin{tabular}[b]{c}
vector\\
\framebox(18,40){$\mathbf{f}$}\\
\end{tabular} & \framebox(18,40){$\frac{\partial \mathbf{f}}{\partial {x}}$} & \framebox(40,40){$\frac{\partial \mathbf{f}}{\partial \mathbf{x}}$}\\
\end{tabular}](images/latex-FEFCAA3AA3D0B051E4960CE52D92A7C0.svg)
The Jacobian of the identity function  , with
, with  , has n functions and each function has n parameters held in a single vector x. The Jacobian is, therefore, a square matrix since :
, has n functions and each function has n parameters held in a single vector x. The Jacobian is, therefore, a square matrix since :

Make sure that you can derive each step above before moving on. If you get stuck, just consider each element of the matrix in isolation and apply the usual scalar derivative rules. That is a generally useful trick: Reduce vector expressions down to a set of scalar expressions and then take all of the partials, combining the results appropriately into vectors and matrices at the end.
Also be careful to track whether a matrix is vertical, x, or horizontal,  where means x transpose. Also make sure you pay attention to whether something is a scalar-valued function,
where means x transpose. Also make sure you pay attention to whether something is a scalar-valued function,  , or a vector of functions (or a vector-valued function),
, or a vector of functions (or a vector-valued function),  .
.
Element-wise binary operations on vectors, such as vector addition  , are important because we can express many common vector operations, such as the multiplication of a vector by a scalar, as element-wise binary operations. By “element-wise binary operations” we simply mean applying an operator to the first item of each vector to get the first item of the output, then to the second items of the inputs for the second item of the output, and so forth. This is how all the basic math operators are applied by default in numpy or tensorflow, for example. Examples that often crop up in deep learning are
, are important because we can express many common vector operations, such as the multiplication of a vector by a scalar, as element-wise binary operations. By “element-wise binary operations” we simply mean applying an operator to the first item of each vector to get the first item of the output, then to the second items of the inputs for the second item of the output, and so forth. This is how all the basic math operators are applied by default in numpy or tensorflow, for example. Examples that often crop up in deep learning are  and
and  (returns a vector of ones and zeros).
(returns a vector of ones and zeros).
We can generalize the element-wise binary operations with notation  where
where  . (Reminder:
. (Reminder:  is the number of items in x.) The
is the number of items in x.) The  symbol represents any element-wise operator (such as
symbol represents any element-wise operator (such as  ) and not the
) and not the  function composition operator. Here's what equation looks like when we zoom in to examine the scalar equations:
function composition operator. Here's what equation looks like when we zoom in to examine the scalar equations:

where we write n (not m) equations vertically to emphasize the fact that the result of element-wise operators give sized vector results.
Using the ideas from the last section, we can see that the general case for the Jacobian with respect to w is the square matrix:

and the Jacobian with respect to x is:

That's quite a furball, but fortunately the Jacobian is very often a diagonal matrix, a matrix that is zero everywhere but the diagonal. Because this greatly simplifies the Jacobian, let's examine in detail when the Jacobian reduces to a diagonal matrix for element-wise operations.
In a diagonal Jacobian, all elements off the diagonal are zero,  where
where  . (Notice that we are taking the partial derivative with respect to wj not wi.) Under what conditions are those off-diagonal elements zero? Precisely when fi and gi are contants with respect to wj,
. (Notice that we are taking the partial derivative with respect to wj not wi.) Under what conditions are those off-diagonal elements zero? Precisely when fi and gi are contants with respect to wj,  . Regardless of the operator, if those partial derivatives go to zero, the operation goes to zero,
. Regardless of the operator, if those partial derivatives go to zero, the operation goes to zero,  no matter what, and the partial derivative of a constant is zero.
no matter what, and the partial derivative of a constant is zero.
Those partials go to zero when fi and gi are not functions of wj. We know that element-wise operations imply that fi is purely a function of wi and gi is purely a function of xi. For example,  sums
sums  . Consequently,
. Consequently,  reduces to
reduces to  and the goal becomes
and the goal becomes  .
.  and
and  look like constants to the partial differentiation operator with respect to wj when so the partials are zero off the diagonal. (Notation is technically an abuse of our notation because fi and gi are functions of vectors not individual elements. We should really write something like
look like constants to the partial differentiation operator with respect to wj when so the partials are zero off the diagonal. (Notation is technically an abuse of our notation because fi and gi are functions of vectors not individual elements. We should really write something like  , but that would muddy the equations further, and programmers are comfortable overloading functions, so we'll proceed with the notation anyway.)
, but that would muddy the equations further, and programmers are comfortable overloading functions, so we'll proceed with the notation anyway.)
We'll take advantage of this simplification later and refer to the constraint that  and
and  access at most wi and xi, respectively, as the element-wise diagonal condition.
access at most wi and xi, respectively, as the element-wise diagonal condition.
Under this condition, the elements along the diagonal of the Jacobian are  :
:

(The large “0”s are a shorthand indicating all of the off-diagonal are 0.)
More succinctly, we can write:

and

where  constructs a matrix whose diagonal elements are taken from vector x.
constructs a matrix whose diagonal elements are taken from vector x.
Because we do lots of simple vector arithmetic, the general function  in the binary element-wise operation is often just the vector w. Any time the general function is a vector, we know that reduces to
in the binary element-wise operation is often just the vector w. Any time the general function is a vector, we know that reduces to  . For example, vector addition
. For example, vector addition  fits our element-wise diagonal condition because
fits our element-wise diagonal condition because  has scalar equations
has scalar equations  that reduce to just
that reduce to just  with partial derivatives:
with partial derivatives:


That gives us  , the identity matrix, because every element along the diagonal is 1. I represents the square identity matrix of appropriate dimensions that is zero everywhere but the diagonal, which contains all ones.
, the identity matrix, because every element along the diagonal is 1. I represents the square identity matrix of appropriate dimensions that is zero everywhere but the diagonal, which contains all ones.
Given the simplicity of this special case, reducing to , you should be able to derive the Jacobians for the common element-wise binary operations on vectors:


The  and
and  operators are element-wise multiplication and division; is sometimes called the Hadamard product. There isn't a standard notation for element-wise multiplication and division so we're using an approach consistent with our general binary operation notation.
operators are element-wise multiplication and division; is sometimes called the Hadamard product. There isn't a standard notation for element-wise multiplication and division so we're using an approach consistent with our general binary operation notation.
When we multiply or add scalars to vectors, we're implicitly expanding the scalar to a vector and then performing an element-wise binary operation. For example, adding scalar z to vector x,  , is really
, is really  where and
where and  . (The notation
. (The notation  represents a vector of ones of appropriate length.) z is any scalar that doesn't depend on x, which is useful because then
represents a vector of ones of appropriate length.) z is any scalar that doesn't depend on x, which is useful because then  for any xi and that will simplify our partial derivative computations. (It's okay to think of variable z as a constant for our discussion here.) Similarly, multiplying by a scalar,
for any xi and that will simplify our partial derivative computations. (It's okay to think of variable z as a constant for our discussion here.) Similarly, multiplying by a scalar,  , is really
, is really  where is the element-wise multiplication (Hadamard product) of the two vectors.
where is the element-wise multiplication (Hadamard product) of the two vectors.
The partial derivatives of vector-scalar addition and multiplication with respect to vector x use our element-wise rule:

This follows because functions and clearly satisfy our element-wise diagonal condition for the Jacobian (that  refer at most to xi and
refer at most to xi and  refers to the value of the
refers to the value of the  vector).
vector).
Using the usual rules for scalar partial derivatives, we arrive at the following diagonal elements of the Jacobian for vector-scalar addition:

So,  .
.
Computing the partial derivative with respect to the scalar parameter z, however, results in a vertical vector, not a diagonal matrix. The elements of the vector are:

Therefore,  .
.
The diagonal elements of the Jacobian for vector-scalar multiplication involve the product rule for scalar derivatives:

So,  .
.
The partial derivative with respect to scalar parameter z is a vertical vector whose elements are:

This gives us  .
.
Summing up the elements of a vector is an important operation in deep learning, such as the network loss function, but we can also use it as a way to simplify computing the derivative of vector dot product and other operations that reduce vectors to scalars.
Let  . Notice we were careful here to leave the parameter as a vector x because each function fi could use all values in the vector, not just xi. The sum is over the results of the function and not the parameter. The gradient (
. Notice we were careful here to leave the parameter as a vector x because each function fi could use all values in the vector, not just xi. The sum is over the results of the function and not the parameter. The gradient ( Jacobian) of vector summation is:
Jacobian) of vector summation is:

(The summation inside the gradient elements can be tricky so make sure to keep your notation consistent.)
Let's look at the gradient of the simple  . The function inside the summation is just and the gradient is then:
. The function inside the summation is just and the gradient is then:

Because  for , we can simplify to:
for , we can simplify to:

Notice that the result is a horizontal vector full of 1s, not a vertical vector, and so the gradient is  . (The T exponent of represents the transpose of the indicated vector. In this case, it flips a vertical vector to a horizontal vector.) It's very important to keep the shape of all of your vectors and matrices in order otherwise it's impossible to compute the derivatives of complex functions.
. (The T exponent of represents the transpose of the indicated vector. In this case, it flips a vertical vector to a horizontal vector.) It's very important to keep the shape of all of your vectors and matrices in order otherwise it's impossible to compute the derivatives of complex functions.
As another example, let's sum the result of multiplying a vector by a constant scalar. If  then
then  . The gradient is:
. The gradient is:

The derivative with respect to scalar variable z is  :
:

We can't compute partial derivatives of very complicated functions using just the basic matrix calculus rules we've seen so far. For example, we can't take the derivative of nested expressions like  directly without reducing it to its scalar equivalent. We need to be able to combine our basic vector rules using what we can call the vector chain rule. Unfortunately, there are a number of rules for differentiation that fall under the name “chain rule” so we have to be careful which chain rule we're talking about. Part of our goal here is to clearly define and name three different chain rules and indicate in which situation they are appropriate. To get warmed up, we'll start with what we'll call the single-variable chain rule, where we want the derivative of a scalar function with respect to a scalar. Then we'll move on to an important concept called the total derivative and use it to define what we'll pedantically call the single-variable total-derivative chain rule. Then, we'll be ready for the vector chain rule in its full glory as needed for neural networks.
directly without reducing it to its scalar equivalent. We need to be able to combine our basic vector rules using what we can call the vector chain rule. Unfortunately, there are a number of rules for differentiation that fall under the name “chain rule” so we have to be careful which chain rule we're talking about. Part of our goal here is to clearly define and name three different chain rules and indicate in which situation they are appropriate. To get warmed up, we'll start with what we'll call the single-variable chain rule, where we want the derivative of a scalar function with respect to a scalar. Then we'll move on to an important concept called the total derivative and use it to define what we'll pedantically call the single-variable total-derivative chain rule. Then, we'll be ready for the vector chain rule in its full glory as needed for neural networks.
The chain rule is conceptually a divide and conquer strategy (like Quicksort) that breaks complicated expressions into subexpressions whose derivatives are easier to compute. Its power derives from the fact that we can process each simple subexpression in isolation yet still combine the intermediate results to get the correct overall result.
The chain rule comes into play when we need the derivative of an expression composed of nested subexpressions. For example, we need the chain rule when confronted with expressions like  . The outermost expression takes the sin of an intermediate result, a nested subexpression that squares x. Specifically, we need the single-variable chain rule, so let's start by digging into that in more detail.
. The outermost expression takes the sin of an intermediate result, a nested subexpression that squares x. Specifically, we need the single-variable chain rule, so let's start by digging into that in more detail.
Let's start with the solution to the derivative of our nested expression:  . It doesn't take a mathematical genius to recognize components of the solution that smack of scalar differentiation rules,
. It doesn't take a mathematical genius to recognize components of the solution that smack of scalar differentiation rules,  and
and  . It looks like the solution is to multiply the derivative of the outer expression by the derivative of the inner expression or “chain the pieces together,” which is exactly right. In this section, we'll explore the general principle at work and provide a process that works for highly-nested expressions of a single variable.
. It looks like the solution is to multiply the derivative of the outer expression by the derivative of the inner expression or “chain the pieces together,” which is exactly right. In this section, we'll explore the general principle at work and provide a process that works for highly-nested expressions of a single variable.
Chain rules are typically defined in terms of nested functions, such as  for single-variable chain rules. (You will also see the chain rule defined using function composition
for single-variable chain rules. (You will also see the chain rule defined using function composition  , which is the same thing.) Some sources write the derivative using shorthand notation
, which is the same thing.) Some sources write the derivative using shorthand notation  , but that hides the fact that we are introducing an intermediate variable:
, but that hides the fact that we are introducing an intermediate variable:  , which we'll see shortly. It's better to define the single-variable chain rule of explicitly so we never take the derivative with respect to the wrong variable. Here is the formulation of the single-variable chain rule we recommend:
, which we'll see shortly. It's better to define the single-variable chain rule of explicitly so we never take the derivative with respect to the wrong variable. Here is the formulation of the single-variable chain rule we recommend:

To deploy the single-variable chain rule, follow these steps:
 is binary,
is binary,  and other trigonometric functions are usually unary because there is a single operand. This step normalizes all equations to single operators or function applications.
and other trigonometric functions are usually unary because there is a single operand. This step normalizes all equations to single operators or function applications.The third step puts the “chain” in “chain rule” because it chains together intermediate results. Multiplying the intermediate derivatives together is the common theme among all variations of the chain rule.
Let's try this process on  :
:
 represent subexpression (shorthand for
represent subexpression (shorthand for  ). This gives us:
). This gives us:

The order of these subexpressions does not affect the answer, but we recommend working in the reverse order of operations dictated by the nesting (innermost to outermost). That way, expressions and derivatives are always functions of previously-computed elements.



Notice how easy it is to compute the derivatives of the intermediate variables in isolation! The chain rule says it's legal to do that and tells us how to combine the intermediate results to get  .
.
You can think of the combining step of the chain rule in terms of units canceling. If we let y be miles, x be the gallons in a gas tank, and u as gallons we can interpret  as
as  . The gallon denominator and numerator cancel.
. The gallon denominator and numerator cancel.
Another way to to think about the single-variable chain rule is to visualize the overall expression as a dataflow diagram or chain of operations (or abstract syntax tree for compiler people):

Changes to function parameter x bubble up through a squaring operation then through a sin operation to change result y. You can think of  as “getting changes from x to u” and
as “getting changes from x to u” and  as “getting changes from u to y.” Getting from x to y requires an intermediate hop. The chain rule is, by convention, usually written from the output variable down to the parameter(s), . But, the x-to-y perspective would be more clear if we reversed the flow and used the equivalent
as “getting changes from u to y.” Getting from x to y requires an intermediate hop. The chain rule is, by convention, usually written from the output variable down to the parameter(s), . But, the x-to-y perspective would be more clear if we reversed the flow and used the equivalent  .
.
Conditions under which the single-variable chain rule applies. Notice that there is a single dataflow path from x to the root y. Changes in x can influence output y in only one way. That is the condition under which we can apply the single-variable chain rule. An easier condition to remember, though one that's a bit looser, is that none of the intermediate subexpression functions,  and
and  , have more than one parameter. Consider
, have more than one parameter. Consider  , which would become
, which would become  after introducing intermediate variable u. As we'll see in the next section,
after introducing intermediate variable u. As we'll see in the next section,  has multiple paths from x to y. To handle that situation, we'll deploy the single-variable total-derivative chain rule.
has multiple paths from x to y. To handle that situation, we'll deploy the single-variable total-derivative chain rule.
| Forward differentiation from x to y | Backward differentiation from y to x |
|---|---|
| |
Automatic differentiation is beyond the scope of this article, but we're setting the stage for a future article.
Many readers can solve  in their heads, but our goal is a process that will work even for very complicated expressions. This process is also how automatic differentiation works in libraries like PyTorch. So, by solving derivatives manually in this way, you're also learning how to define functions for custom neural networks in PyTorch.
in their heads, but our goal is a process that will work even for very complicated expressions. This process is also how automatic differentiation works in libraries like PyTorch. So, by solving derivatives manually in this way, you're also learning how to define functions for custom neural networks in PyTorch.
With deeply nested expressions, it helps to think about deploying the chain rule the way a compiler unravels nested function calls like  into a sequence (chain) of calls. The result of calling function fi is saved to a temporary variable called a register, which is then passed as a parameter to
into a sequence (chain) of calls. The result of calling function fi is saved to a temporary variable called a register, which is then passed as a parameter to  . Let's see how that looks in practice by using our process on a highly-nested equation like
. Let's see how that looks in practice by using our process on a highly-nested equation like  :
:




Here is a visualization of the data flow through the chain of operations from x to y:

At this point, we can handle derivatives of nested expressions of a single variable, x, using the chain rule but only if x can affect y through a single data flow path. To handle more complicated expressions, we need to extend our technique, which we'll do next.
Our single-variable chain rule has limited applicability because all intermediate variables must be functions of single variables. But, it demonstrates the core mechanism of the chain rule, that of multiplying out all derivatives of intermediate subexpressions. To handle more general expressions such as  , however, we need to augment that basic chain rule.
, however, we need to augment that basic chain rule.
Of course, we immediately see  , but that is using the scalar addition derivative rule, not the chain rule. If we tried to apply the single-variable chain rule, we'd get the wrong answer. In fact, the previous chain rule is meaningless in this case because derivative operator does not apply to multivariate functions, such as
, but that is using the scalar addition derivative rule, not the chain rule. If we tried to apply the single-variable chain rule, we'd get the wrong answer. In fact, the previous chain rule is meaningless in this case because derivative operator does not apply to multivariate functions, such as  among our intermediate variables:
among our intermediate variables:

Let's try it anyway to see what happens. If we pretend that  and
and  , then
, then  instead of the right answer
instead of the right answer  .
.
Because  has multiple parameters, partial derivatives come into play. Let's blindly apply the partial derivative operator to all of our equations and see what we get:
has multiple parameters, partial derivatives come into play. Let's blindly apply the partial derivative operator to all of our equations and see what we get:

Ooops! The partial  is wrong because it violates a key assumption for partial derivatives. When taking the partial derivative with respect to x, the other variables must not vary as x varies. Otherwise, we could not act as if the other variables were constants. Clearly, though,
is wrong because it violates a key assumption for partial derivatives. When taking the partial derivative with respect to x, the other variables must not vary as x varies. Otherwise, we could not act as if the other variables were constants. Clearly, though,  is a function of x and therefore varies with x.
is a function of x and therefore varies with x.  because
because  . A quick look at the data flow diagram for
. A quick look at the data flow diagram for  shows multiple paths from x to y, thus, making it clear we need to consider direct and indirect (through
shows multiple paths from x to y, thus, making it clear we need to consider direct and indirect (through  ) dependencies on x:
) dependencies on x:
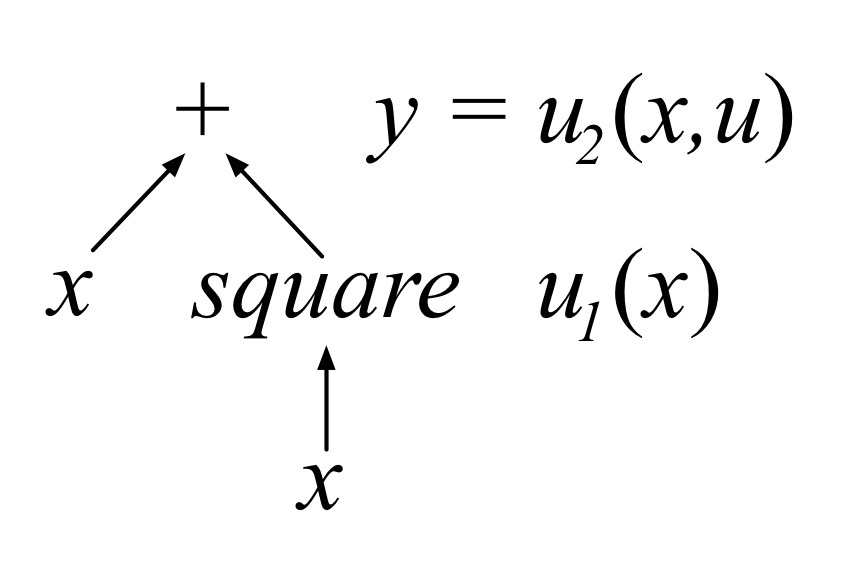
A change in x affects y both as an operand of the addition and as the operand of the square operator. Here's an equation that describes how tweaks to x affect the output:

Then,  , which we can read as “the change in y is the difference between the original y and y at a tweaked x.”
, which we can read as “the change in y is the difference between the original y and y at a tweaked x.”
If we let  , then
, then  . If we bump x by 1,
. If we bump x by 1,  , then
, then  . The change in y is not
. The change in y is not  , as
, as  would lead us to believe, but
would lead us to believe, but  !
!
Enter the “law” of total derivatives, which basically says that to compute  , we need to sum up all possible contributions from changes in x to the change in y. The total derivative with respect to x assumes all variables, such as
, we need to sum up all possible contributions from changes in x to the change in y. The total derivative with respect to x assumes all variables, such as  in this case, are functions of x and potentially vary as x varies. The total derivative of
in this case, are functions of x and potentially vary as x varies. The total derivative of  that depends on x directly and indirectly via intermediate variable is given by:
that depends on x directly and indirectly via intermediate variable is given by:

Using this formula, we get the proper answer:

That is an application of what we can call the single-variable total-derivative chain rule:

The total derivative assumes all variables are potentially codependent whereas the partial derivative assumes all variables but x are constants.
There is something subtle going on here with the notation. All of the derivatives are shown as partial derivatives because f and ui are functions of multiple variables. This notation mirrors that of MathWorld's notation but differs from Wikipedia, which uses  instead (possibly to emphasize the total derivative nature of the equation). We'll stick with the partial derivative notation so that it's consistent with our discussion of the vector chain rule in the next section.
instead (possibly to emphasize the total derivative nature of the equation). We'll stick with the partial derivative notation so that it's consistent with our discussion of the vector chain rule in the next section.
In practice, just keep in mind that when you take the total derivative with respect to x, other variables might also be functions of x so add in their contributions as well. The left side of the equation looks like a typical partial derivative but the right-hand side is actually the total derivative. It's common, however, that many temporary variables are functions of a single parameter, which means that the single-variable total-derivative chain rule degenerates to the single-variable chain rule.
Let's look at a nested subexpression, such as  . We introduce three intermediate variables:
. We introduce three intermediate variables:

and partials:

where both  and
and  have
have  terms that take into account the total derivative.
terms that take into account the total derivative.
Also notice that the total derivative formula always sums versus, say, multiplies terms  . It's tempting to think that summing up terms in the derivative makes sense because, for example,
. It's tempting to think that summing up terms in the derivative makes sense because, for example,  adds two terms. Nope. The total derivative is adding terms because it represents a weighted sum of all x contributions to the change in y. For example, given
adds two terms. Nope. The total derivative is adding terms because it represents a weighted sum of all x contributions to the change in y. For example, given  instead of
instead of  , the total-derivative chain rule formula still adds partial derivative terms. (
, the total-derivative chain rule formula still adds partial derivative terms. ( simplifies to
simplifies to  but for this demonstration, let's not combine the terms.) Here are the intermediate variables and partial derivatives:
but for this demonstration, let's not combine the terms.) Here are the intermediate variables and partial derivatives:

The form of the total derivative remains the same, however:

It's the partials (weights) that change, not the formula, when the intermediate variable operators change.
Those readers with a strong calculus background might wonder why we aggressively introduce intermediate variables even for the non-nested subexpressions such as in  . We use this process for three reasons: (i) computing the derivatives for the simplified subexpressions is usually trivial, (ii) we can simplify the chain rule, and (iii) the process mirrors how automatic differentiation works in neural network libraries.
. We use this process for three reasons: (i) computing the derivatives for the simplified subexpressions is usually trivial, (ii) we can simplify the chain rule, and (iii) the process mirrors how automatic differentiation works in neural network libraries.
Using the intermediate variables even more aggressively, let's see how we can simplify our single-variable total-derivative chain rule to its final form. The goal is to get rid of the  sticking out on the front like a sore thumb:
sticking out on the front like a sore thumb:

We can achieve that by simply introducing a new temporary variable as an alias for x:  . Then, the formula reduces to our final form:
. Then, the formula reduces to our final form:

This total-derivative chain rule degenerates to the single-variable chain rule when all intermediate variables are functions of a single variable. Consequently, you can remember this more general formula to cover both cases. As a bit of dramatic foreshadowing, notice that the summation sure looks like a vector dot product,  , or a vector multiply
, or a vector multiply  .
.
Before we move on, a word of caution about terminology on the web. Unfortunately, the chain rule given in this section, based upon the total derivative, is universally called “multivariable chain rule” in calculus discussions, which is highly misleading! Only the intermediate variables are multivariate functions. The overall function, say,  , is a scalar function that accepts a single parameter x. The derivative and parameter are scalars, not vectors, as one would expect with a so-called multivariate chain rule. (Within the context of a non-matrix calculus class, “multivariate chain rule” is likely unambiguous.) To reduce confusion, we use “single-variable total-derivative chain rule” to spell out the distinguishing feature between the simple single-variable chain rule,
, is a scalar function that accepts a single parameter x. The derivative and parameter are scalars, not vectors, as one would expect with a so-called multivariate chain rule. (Within the context of a non-matrix calculus class, “multivariate chain rule” is likely unambiguous.) To reduce confusion, we use “single-variable total-derivative chain rule” to spell out the distinguishing feature between the simple single-variable chain rule,  , and this one.
, and this one.
Now that we've got a good handle on the total-derivative chain rule, we're ready to tackle the chain rule for vectors of functions and vector variables. Surprisingly, this more general chain rule is just as simple looking as the single-variable chain rule for scalars. Rather than just presenting the vector chain rule, let's rediscover it ourselves so we get a firm grip on it. We can start by computing the derivative of a sample vector function with respect to a scalar,  , to see if we can abstract a general formula.
, to see if we can abstract a general formula.

Let's introduce two intermediate variables,  and
and  , one for each fi so that y looks more like
, one for each fi so that y looks more like  :
:


The derivative of vector y with respect to scalar x is a vertical vector with elements computed using the single-variable total-derivative chain rule:

Ok, so now we have the answer using just the scalar rules, albeit with the derivatives grouped into a vector. Let's try to abstract from that result what it looks like in vector form. The goal is to convert the following vector of scalar operations to a vector operation.

If we split the  terms, isolating the
terms, isolating the  terms into a vector, we get a matrix by vector multiplication:
terms into a vector, we get a matrix by vector multiplication:

That means that the Jacobian is the multiplication of two other Jacobians, which is kinda cool. Let's check our results:

Whew! We get the same answer as the scalar approach. This vector chain rule for vectors of functions and a single parameter appears to be correct and, indeed, mirrors the single-variable chain rule. Compare the vector rule:

with the single-variable chain rule:

To make this formula work for multiple parameters or vector x, we just have to change x to vector x in the equation. The effect is that  and the resulting Jacobian,
and the resulting Jacobian,  , are now matrices instead of vertical vectors. Our complete vector chain rule is:
, are now matrices instead of vertical vectors. Our complete vector chain rule is:

The beauty of the vector formula over the single-variable chain rule is that it automatically takes into consideration the total derivative while maintaining the same notational simplicity. The Jacobian contains all possible combinations of fi with respect to gj and gi with respect to xj. For completeness, here are the two Jacobian components in their full glory:

where  ,
,  , and
, and  . The resulting Jacobian is (an
. The resulting Jacobian is (an  matrix multiplied by a
matrix multiplied by a  matrix).
matrix).
Even within this  formula, we can simplify further because, for many applications, the Jacobians are square () and the off-diagonal entries are zero. It is the nature of neural networks that the associated mathematics deals with functions of vectors not vectors of functions. For example, the neuron affine function has term
formula, we can simplify further because, for many applications, the Jacobians are square () and the off-diagonal entries are zero. It is the nature of neural networks that the associated mathematics deals with functions of vectors not vectors of functions. For example, the neuron affine function has term  and the activation function is
and the activation function is  ; we'll consider derivatives of these functions in the next section.
; we'll consider derivatives of these functions in the next section.
As we saw in a previous section, element-wise operations on vectors w and x yield diagonal matrices with elements  because wi is a function purely of xi but not xj for . The same thing happens here when fi is purely a function of gi and gi is purely a function of xi:
because wi is a function purely of xi but not xj for . The same thing happens here when fi is purely a function of gi and gi is purely a function of xi:


In this situation, the vector chain rule simplifies to:

Therefore, the Jacobian reduces to a diagonal matrix whose elements are the single-variable chain rule values.
After slogging through all of that mathematics, here's the payoff. All you need is the vector chain rule because the single-variable formulas are special cases of the vector chain rule. The following table summarizes the appropriate components to multiply in order to get the Jacobian.
![\begin{tabular}[t]{c|cccc}
&
\multicolumn{2}{c}{
\begin{tabular}[t]{c}
scalar\\
\framebox(18,18){$x$}\\
\end{tabular}} & &\begin{tabular}{c}
vector\\
\framebox(18,40){$\mathbf{x}$}\\
\end{tabular} \\
\begin{tabular}{c}$\frac{\partial}{\partial \mathbf{x}} \mathbf{f}(\mathbf{g}(\mathbf{x}))$
= $\frac{\partial \mathbf{f}}{\partial \mathbf{g}}\frac{\partial\mathbf{g}}{\partial \mathbf{x}}$
\\
\end{tabular} & \begin{tabular}[t]{c}
scalar\\
\framebox(18,18){$u$}\\
\end{tabular} & \begin{tabular}{c}
vector\\
\framebox(18,40){$\mathbf{u}$}
\end{tabular}& & \begin{tabular}{c}
vector\\
\framebox(18,40){$\mathbf{u}$}\\
\end{tabular} \\
\hline
%\[dimexpr-\normalbaselineskip+5pt]
\begin{tabular}[b]{c}
scalar\\
\framebox(18,18){$f$}\\
\end{tabular} &\framebox(18,18){$\frac{\partial f}{\partial {u}}$} \framebox(18,18){$\frac{\partial u}{\partial {x}}$} ~~~& \raisebox{22pt}{\framebox(40,18){$\frac{\partial f}{\partial {\mathbf{u}}}$}} \framebox(18,40){$\frac{\partial \mathbf{u}}{\partial x}$} & ~~~&
\raisebox{22pt}{\framebox(40,18){$\frac{\partial f}{\partial {\mathbf{u}}}$}} \framebox(40,40){$\frac{\partial \mathbf{u}}{\partial \mathbf{x}}$}
\\
\begin{tabular}[b]{c}
vector\\
\framebox(18,40){$\mathbf{f}$}\\
\end{tabular} & \framebox(18,40){$\frac{\partial \mathbf{f}}{\partial {u}}$} \raisebox{22pt}{\framebox(18,18){$\frac{\partial u}{\partial {x}}$}} & \framebox(40,40){$\frac{\partial \mathbf{f}}{\partial \mathbf{u}}$} \framebox(18,40){$\frac{\partial \mathbf{u}}{\partial x}$} & & \framebox(40,40){$\frac{\partial \mathbf{f}}{\partial \mathbf{u}}$} \framebox(40,40){$\frac{\partial \mathbf{u}}{\partial \mathbf{x}}$}\\
\end{tabular}](images/latex-60482D46C45EEE61345A44D34A6BDEFA.svg)
We now have all of the pieces needed to compute the derivative of a typical neuron activation for a single neural network computation unit with respect to the model parameters, w and b:

(This represents a neuron with fully connected weights and rectified linear unit activation. There are, however, other affine functions such as convolution and other activation functions, such as exponential linear units, that follow similar logic.)
Let's worry about max later and focus on computing  and
and  . (Recall that neural networks learn through optimization of their weights and biases.) We haven't discussed the derivative of the dot product yet,
. (Recall that neural networks learn through optimization of their weights and biases.) We haven't discussed the derivative of the dot product yet,  , but we can use the chain rule to avoid having to memorize yet another rule. (Note notation y not y as the result is a scalar not a vector.)
, but we can use the chain rule to avoid having to memorize yet another rule. (Note notation y not y as the result is a scalar not a vector.)
The dot product  is just the summation of the element-wise multiplication of the elements:
is just the summation of the element-wise multiplication of the elements:  . (You might also find it useful to remember the linear algebra notation
. (You might also find it useful to remember the linear algebra notation  .) We know how to compute the partial derivatives of
.) We know how to compute the partial derivatives of  and
and  but haven't looked at partial derivatives for
but haven't looked at partial derivatives for  . We need the chain rule for that and so we can introduce an intermediate vector variable u just as we did using the single-variable chain rule:
. We need the chain rule for that and so we can introduce an intermediate vector variable u just as we did using the single-variable chain rule:

Once we've rephrased y, we recognize two subexpressions for which we already know the partial derivatives:

The vector chain rule says to multiply the partials:

To check our results, we can grind the dot product down into a pure scalar function:

Then:

Hooray! Our scalar results match the vector chain rule results.
Now, let  , the full expression within the max activation function call. We have two different partials to compute, but we don't need the chain rule:
, the full expression within the max activation function call. We have two different partials to compute, but we don't need the chain rule:

Let's tackle the partials of the neuron activation,  . The use of the
. The use of the  function call on scalar z just says to treat all negative z values as 0. The derivative of the max function is a piecewise function. When
function call on scalar z just says to treat all negative z values as 0. The derivative of the max function is a piecewise function. When  , the derivative is 0 because z is a constant. When
, the derivative is 0 because z is a constant. When  , the derivative of the max function is just the derivative of z, which is :
, the derivative of the max function is just the derivative of z, which is :
 , we broadcast the single-variable function max across the elements. This is an example of an element-wise unary operator. Just to be clear:
, we broadcast the single-variable function max across the elements. This is an example of an element-wise unary operator. Just to be clear:

For the derivative of the broadcast version then, we get a vector of zeros and ones where:


To get the derivative of the  function, we need the chain rule because of the nested subexpression,
function, we need the chain rule because of the nested subexpression,  . Following our process, let's introduce intermediate scalar variable z to represent the affine function giving:
. Following our process, let's introduce intermediate scalar variable z to represent the affine function giving:


The vector chain rule tells us:

which we can rewrite as follows:

and then substitute  back in:
back in:

That equation matches our intuition. When the activation function clips affine function output z to 0, the derivative is zero with respect to any weight wi. When , it's as if the max function disappears and we get just the derivative of z with respect to the weights.
Turning now to the derivative of the neuron activation with respect to b, we get:

Let's use these partial derivatives now to handle the entire loss function.
Training a neuron requires that we take the derivative of our loss or “cost” function with respect to the parameters of our model, w and b. For this example, we'll use mean-squared-error as our loss function. Because we train with multiple vector inputs (e.g., multiple images) and scalar targets (e.g., one classification per image), we need some more notation. Let

where  , and then let
, and then let

where yi is a scalar. Then the cost equation becomes:

Following our chain rule process introduces these intermediate variables:

Let's compute the gradient with respect to w first.
From before, we know:

and

Then, for the overall gradient, we get:

To interpret that equation, we can substitute an error term  yielding:
yielding:

From there, notice that this computation is a weighted average across all xi in X. The weights are the error terms, the difference between the target output and the actual neuron output for each xi input. The resulting gradient will, on average, point in the direction of higher cost or loss because large ei emphasize their associated xi. Imagine we only had one input vector,  , then the gradient is just
, then the gradient is just  . If the error is 0, then the gradient is zero and we have arrived at the minimum loss. If
. If the error is 0, then the gradient is zero and we have arrived at the minimum loss. If  is some small positive difference, the gradient is a small step in the direction of
is some small positive difference, the gradient is a small step in the direction of  . If is large, the gradient is a large step in that direction. If is negative, the gradient is reversed, meaning the highest cost is in the negative direction.
. If is large, the gradient is a large step in that direction. If is negative, the gradient is reversed, meaning the highest cost is in the negative direction.
Of course, we want to reduce, not increase, the loss, which is why the gradient descent recurrence relation takes the negative of the gradient to update the current position (for scalar learning rate  ):
):

Because the gradient indicates the direction of higher cost, we want to update w in the opposite direction.
To optimize the bias, b, we also need the partial with respect to b. Here are the intermediate variables again:

We computed the partial with respect to the bias for equation  previously:
previously:

For v, the partial is:

And for the partial of the cost function itself we get:

As before, we can substitute an error term:

The partial derivative is then just the average of the error or zero, according to the activation level. To update the neuron bias, we nudge it in the opposite direction of increased cost:

In practice, it is convenient to combine w and b into a single vector parameter rather than having to deal with two different partials:  . This requires a tweak to the input vector x as well but simplifies the activation function. By tacking a 1 onto the end of x,
. This requires a tweak to the input vector x as well but simplifies the activation function. By tacking a 1 onto the end of x,  , becomes
, becomes  .
.
This finishes off the optimization of the neural network loss function because we have the two partials necessary to perform a gradient descent.
Hopefully you've made it all the way through to this point. You're well on your way to understanding matrix calculus! We've included a reference that summarizes all of the rules from this article in the next section. Also check out the annotated resource link below.
Your next step would be to learn about the partial derivatives of matrices not just vectors. For example, you can take a look at the matrix differentiation section of Matrix calculus.
Acknowledgements. We thank Yannet Interian (Faculty in MS data science program at University of San Francisco) and David Uminsky (Faculty/director of MS data science) for their help with the notation presented here.
The gradient of a function of two variables is a horizontal 2-vector:

The Jacobian of a vector-valued function that is a function of a vector is an ( and ) matrix containing all possible scalar partial derivatives:
and ) matrix containing all possible scalar partial derivatives:

The Jacobian of the identity function is I.
Define generic element-wise operations on vectors w and x using operator such as :

The Jacobian with respect to w (similar for x) is:
Given the constraint (element-wise diagonal condition) that and access at most wi and xi, respectively, the Jacobian simplifies to a diagonal matrix:
Here are some sample element-wise operators:

Adding scalar z to vector x, , is really where and .


Scalar multiplication yields:


The partial derivative of a vector sum with respect to one of the vectors is:

For :

For  and
and  , we get:
, we get:


Vector dot product  . Substituting
. Substituting  and using the vector chain rule, we get:
and using the vector chain rule, we get:

Similarly,  .
.
The vector chain rule is the general form as it degenerates to the others. When f is a function of a single variable x and all intermediate variables u are functions of a single variable, the single-variable chain rule applies. When some or all of the intermediate variables are functions of multiple variables, the single-variable total-derivative chain rule applies. In all other cases, the vector chain rule applies.
| Single-variable rule | Single-variable total-derivative rule | Vector rule |
|---|---|---|
 |  |  |
Lowercase letters in bold font such as x are vectors and those in italics font like x are scalars. xi is the element of vector x and is in italics because a single vector element is a scalar. means “length of vector x.”
The T exponent of represents the transpose of the indicated vector.
 is just a for-loop that iterates i from a to b, summing all the xi.
is just a for-loop that iterates i from a to b, summing all the xi.
Notation refers to a function called f with an argument of x.
I represents the square “identity matrix” of appropriate dimensions that is zero everywhere but the diagonal, which contains all ones.
constructs a matrix whose diagonal elements are taken from vector x.
The dot product is the summation of the element-wise multiplication of the elements: . Or, you can look at it as  .
.
Differentiation is an operator that maps a function of one parameter to another function. That means that maps to its derivative with respect to x, which is the same thing as . Also, if , then .
The partial derivative of the function with respect to x,  , performs the usual scalar derivative holding all other variables constant.
, performs the usual scalar derivative holding all other variables constant.
The gradient of f with respect to vector x,  , organizes all of the partial derivatives for a specific scalar function.
, organizes all of the partial derivatives for a specific scalar function.
The Jacobian organizes the gradients of multiple functions into a matrix by stacking them:

The following notation means that y has the value a upon  and value b upon
and value b upon  .
.

Wolfram Alpha can do symbolic matrix algebra and there is also a cool dedicated matrix calculus differentiator.
When looking for resources on the web, search for “matrix calculus” not “vector calculus.” Here are some comments on the top links that come up from a Google search:
The Wikipedia entry is actually quite good and they have a good description of the different layout conventions. Recall that we use the numerator layout where the variables go horizontally and the functions go vertically in the Jacobian. Wikipedia also has a good description of total derivatives, but be careful that they use slightly different notation than we do. We always use the  notation not dx.
notation not dx.
This page has a section on matrix differentiation with some useful identities; this person uses numerator layout. This might be a good place to start after reading this article to learn about matrix versus vector differentiation.
This is part of the course notes for “Introduction to Finite Element Methods” I believe by Carlos A. Felippa. His Jacobians are transposed from our notation because he uses denominator layout.
This page has a huge number of useful derivatives computed for a variety of vectors and matrices. A great cheat sheet. There is no discussion to speak of, just a set of rules.
Another cheat sheet that focuses on matrix operations in general with more discussion than the previous item.
A useful set of slides.
To learn more about neural networks and the mathematics behind optimization and back propagation, we highly recommend Michael Nielsen's book.
For those interested specifically in convolutional neural networks, check out A guide to convolution arithmetic for deep learning.
We reference the law of total derivative, which is an important concept that just means derivatives with respect to x must take into consideration the derivative with respect x of all variables that are a function of x.